GPT-SoVITS,克隆聲音,一分鐘就可以複製你的聲音.

GPT-SoVITS
官方的Github 連結
這個專案在一月中開始之後有一直在注意,今天來實作一下.
專案主 是 billbill 的花月不哭
當初發布的時候的video
這邊有一篇他的文章也可以參考
當初 2,3 百個 start 到了現在已經有 15.3K 的 start 是真的蠻厲害的.
這個專案把整個流程整合成為一個 webGUI 的方式做整合.
現在試玩後,對於克隆出來的聲音因該說堪用但是還是聽得出來是機器產出的,但是對於訓練出來的聲音可以使用不同的語言這個部分就蠻驚訝的.
對於商用的部分可能有幾個方式可以參考或是來玩看看
語言教學方面
即時多語言翻譯語音
- 可能搭配小的語言模型 7B 因該就夠用
- 說故事頻道
- 搭配圖片輸出做 Youtube
- Procast 方式?
- 最可能的方式大概是小孩市場
- 語音客服
- 這個可能就要跟企業端坐客製
- 心靈健康
- 衍伸方面可能是心靈部分 包含陪伴跟情感
- 冥想也是一個
- 打發無聊也是
- 以上這些可能就需要大一點的模型 可能還是串接 chatGPT 才可能有好的效果,語音在這事會比文字更好的訊息媒介.
記錄一下 Mac 安裝方式
基礎條件
搭載 Apple 晶片的 Mac
macOS 12.3 或更高版本
已透過運行 xcode-select –install 安裝 Xcode command-line tools
安裝 anaconda
先前往 anaconda 下載
然後更新一下
1
conda update conda
安裝 ffmpeg
1
2
brew install ffmpeg
ffmpeg -version
這個要確定版本要大於 6.1
環境設定
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
1
2
3
4
5
6
7
8
9
10
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
cd GPT-SoVITS
conda create -n GPTSoVits python=3.9
conda activate GPTSoVits
bash install.sh
這邊要注意 因為用 bash 安裝的時候 他會安裝 ffmapg 會是舊的 4.1 版本
1
2
conda list ffmpeg
conda remove ffmpeg
看一下版本有的話就移除
啟動
1
pyhton webui.py
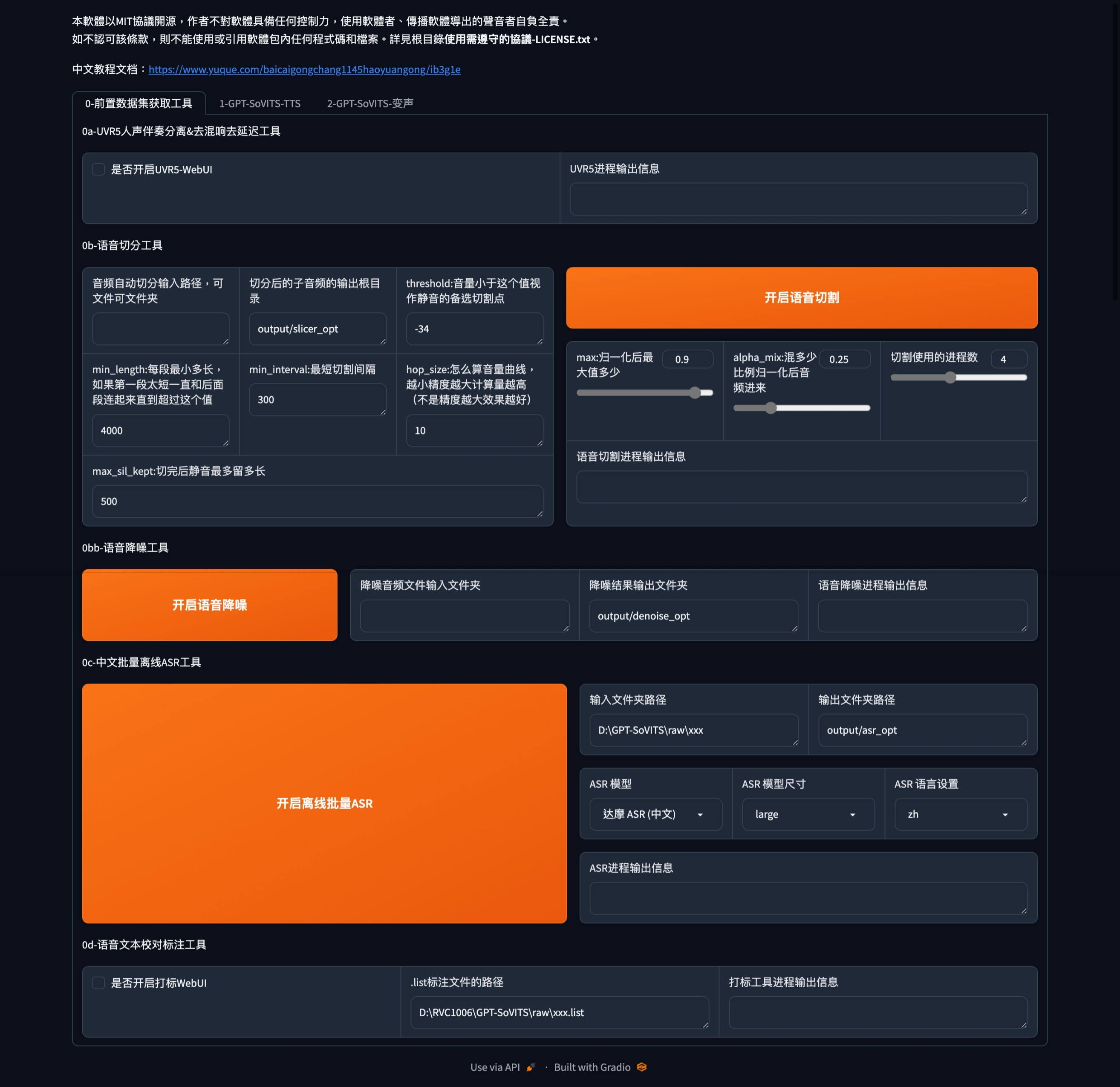
素材準備
聲音獲取並且提取人聲
工具裡面第一個是 UVR5 這個是一個 opensource 的聲音樂器分離的工具 可以看他的github
如果錄音的時候直接只有一個人聲就不需要另外提取
這邊要注意到 一次就是一個聲音不能一次兩個不同聲音來訓練
聲音切片
自動語音識別 ASR
語音本文
訓練
推理
本文章以 CC BY 4.0 授權